Stanford: Self improving Meta-Harness
Stanford vừa giới thiệu Meta-Harness, một hệ thống tự cải thiện bản thân dành cho các mô hình LLM. Trước đó, chúng ta đã có Prompt engineering, rồi Context engineering, sau đó là Agents và Harness. Giờ đây, Meta Harness giúp tự động sửa lỗi của agent và nâng cao hiệu suất, đồng thời sử dụng ít context hơn:
[https://arxiv.org/abs/2603.28052](https://arxiv.org/abs/2603.28052)
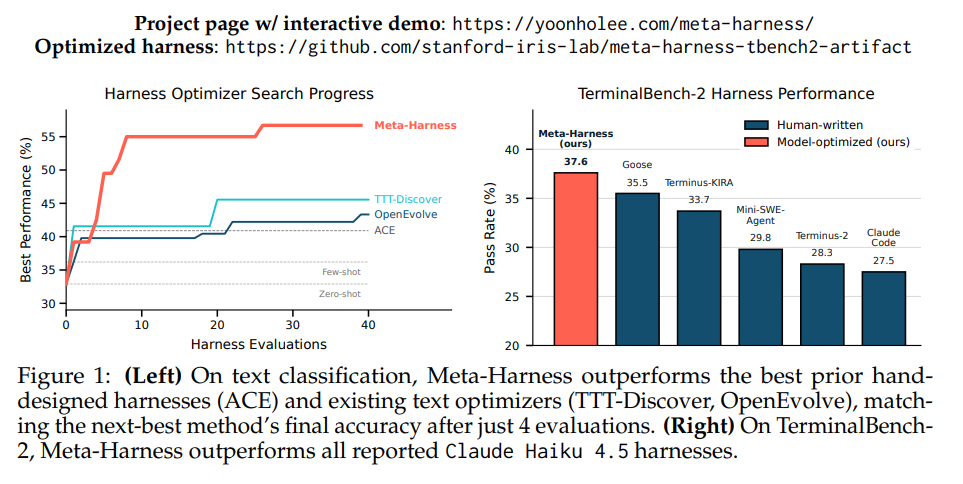
"Hiệu suất của hệ thống mô hình ngôn ngữ lớn (LLM) không chỉ phụ thuộc vào trọng số của mô hình, mà còn vào harness – phần mã quyết định thông tin nào sẽ được lưu trữ, truy xuất và trình bày cho mô hình. Tuy nhiên, phần harness vẫn chủ yếu do con người thiết kế thủ công, và các trình tối ưu hóa văn bản hiện tại chưa phù hợp vì chúng thường nén feedback quá mức. Chúng tôi giới thiệu Meta-Harness, một hệ thống lặp bên ngoài tìm kiếm qua mã harness dành cho các ứng dụng LLM. Nó sử dụng một proposer có khả năng truy cập mã nguồn, điểm số và trace của các ứng viên trước đó qua hệ thống file. Trên tác vụ phân loại văn bản trực tuyến, Meta-Harness vượt xa hệ thống quản lý context hiện tại với điểm số cao hơn 7.7 điểm và sử dụng ít tokens hơn gấp 4 lần. Trong giải toán hỗ trợ truy xuất, một harness được phát hiện giúp nâng cao độ chính xác trung bình 4.7 điểm trên 200 đề thi IMO qua năm mô hình kiểm thử. Trong lập trình agentic, các harness phát hiện vượt qua các baseline do con người thiết kế tốt nhất trên TerminalBench-2. Tóm lại, những kết quả này cho thấy việc truy cập nhiều hơn vào kinh nghiệm trước đó có thể giúp tự động hóa việc thiết kế harness."
Có vẻ như việc nâng cao hiệu suất này khá đơn giản để áp dụng cho các LLM cài đặt địa phương, vì bạn có thể chạy hệ thống này sau các tác vụ chính để sửa lỗi hoặc cải thiện dự án. Tham khảo mã nguồn mở tại: [https://github.com/stanford-iris-lab/meta-harness-tbench2-artifact](https://github.com/stanford-iris-lab/meta-harness-tbench2-artifact)