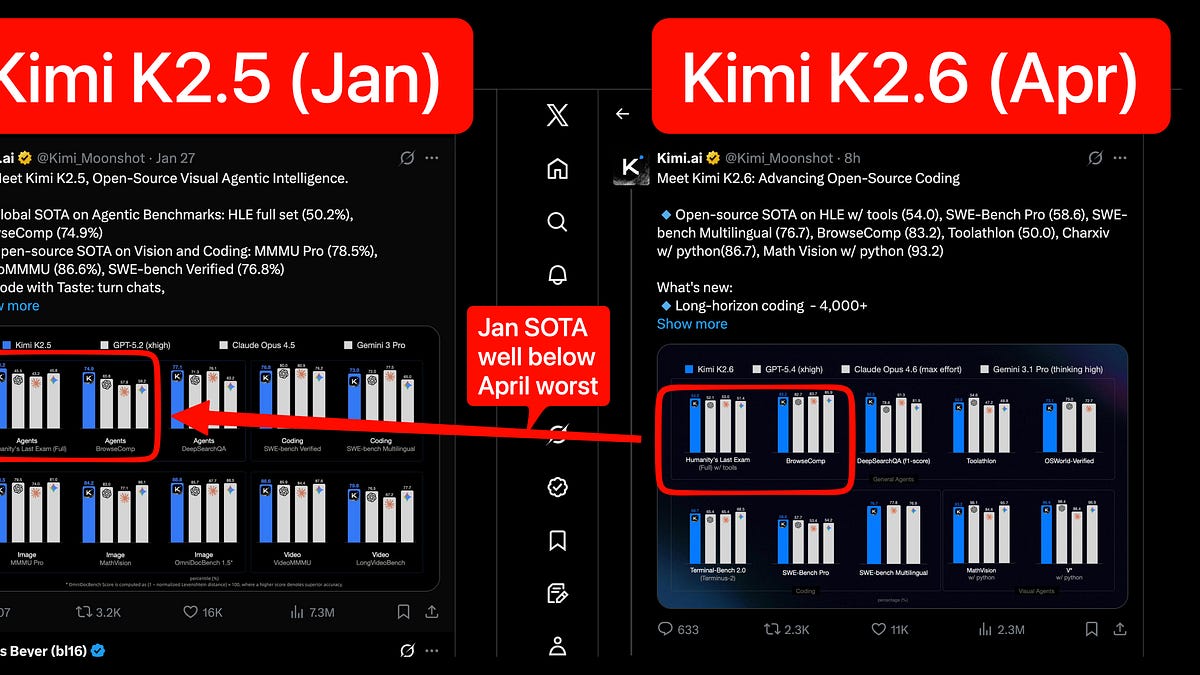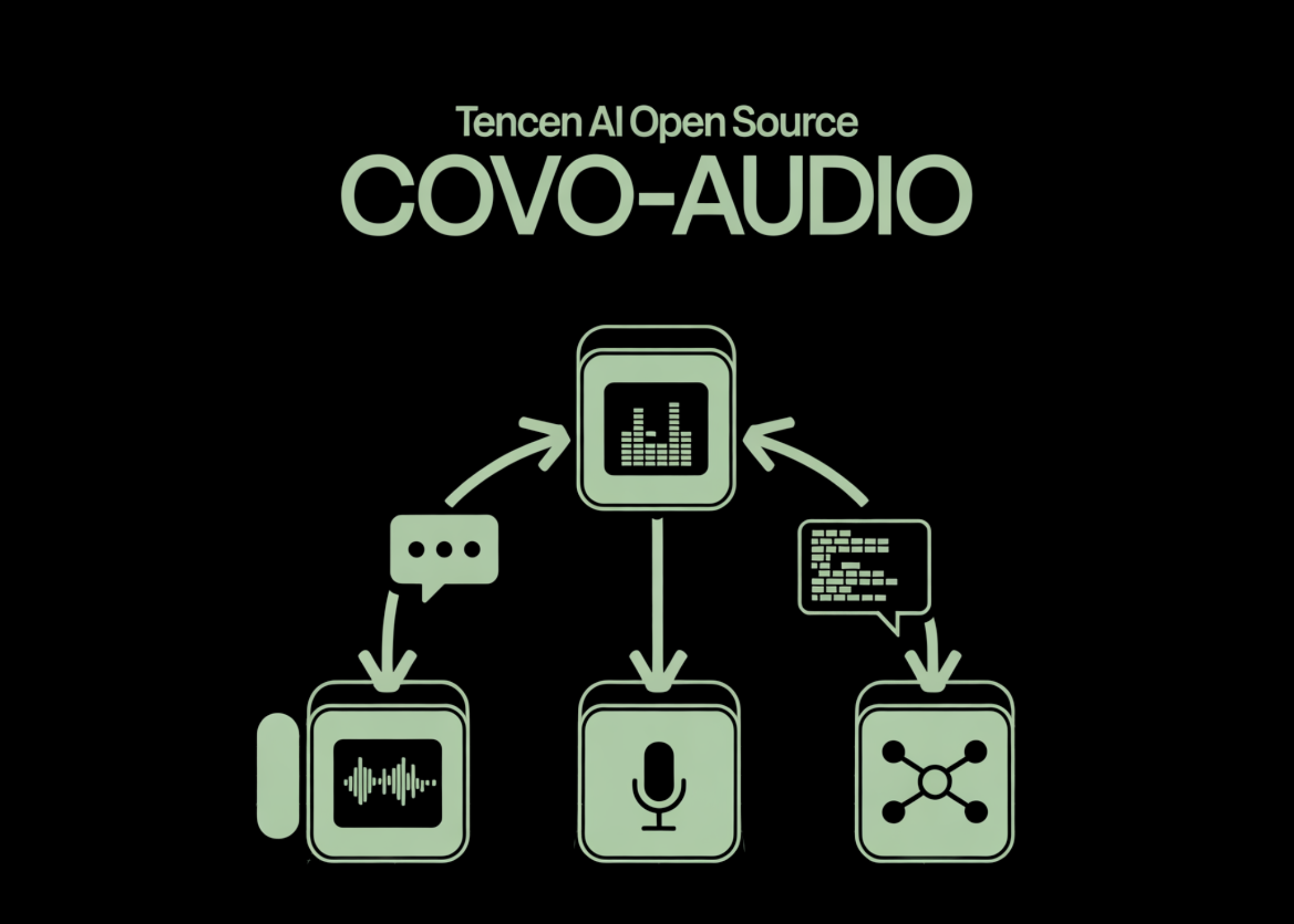
Tencent AI Lab đã chính thức mở mã nguồn Covo-Audio, một Mô hình Ngôn ngữ Âm thanh Lớn (LALM) với 7 tỷ tham số, được thiết kế để thống nhất xử lý giọng nói và trí tuệ ngôn ngữ. Đây là bước tiến quan trọng hướng tới các hệ thống AI có khả năng hội thoại âm thanh tự nhiên, thời gian thực và lập luận phức tạp trong một kiến trúc duy nhất.
Kiến trúc hệ thống và chiến lược đan xen đa phương thức
Khung Covo-Audio bao gồm bốn thành phần chính: một bộ mã hóa âm thanh dựa trên Whisper để xử lý đầu vào, một bộ chuyển đổi chuyên dụng để kết nối với mô hình ngôn ngữ lớn (LLM), LLM đã được điều chỉnh để xử lý chuỗi đan xen giữa đặc trưng âm thanh và văn bản, và một bộ tạo giọng nói (vocoder) để tái tạo âm thanh chất lượng cao. Một đóng góp cốt lõi của nghiên cứu là chiến lược Đan xen Ba phương thức Phân cấp, cho phép căn chỉnh các đặc trưng âm thanh liên tục với văn bản và mã token âm thanh rời rạc ở cả cấp độ cụm từ và câu, đảm bảo tính mạch lạc về ngữ nghĩa.
Tách biệt trí tuệ và giọng nói để tùy biến linh hoạt
Để giải quyết chi phí cao của việc xây dựng dữ liệu hội thoại quy mô lớn cho từng người nói cụ thể, nhóm nghiên cứu đề xuất chiến lược Tách biệt Trí tuệ - Người nói. Kỹ thuật này tách biệt khả năng hội thoại thông minh khỏi quá trình tạo giọng nói, cho phép tùy chỉnh giọng nói linh hoạt chỉ với một lượng nhỏ dữ liệu tổng hợp giọng nói (TTS). Điều này mở ra khả năng tương tác cá nhân hóa mà không cần đến các bộ dữ liệu hội thoại khổng lồ.
Hội thoại thời gian thực và lập luận nâng cao
Mô hình hỗ trợ hội thoại thời gian thực thông qua cơ chế truyền phát theo đoạn kép, cho phép giao tiếp hai chiều đồng thời. Hệ thống quản lý trạng thái hội thoại bằng các token kiến trúc đặc biệt để chỉ định trạng thái lắng nghe, chuyển lượt nói và phát hiện ngắt lời. Để nâng cao khả năng lập luận phức tạp, mô hình tích hợp Tối ưu hóa Chính sách Tương đối Nhóm (GRPO) và được tối ưu bằng một hàm thưởng tổng hợp có thể xác minh, tập trung vào độ chính xác, định dạng, tính nhất quán và tư duy.
Kết quả đánh giá và hiệu suất
Covo-Audio (7B) cho thấy kết quả cạnh tranh hoặc vượt trội trên một số điểm chuẩn. Trên bộ Speechtext-LLM-Bench, nó đạt điểm trung bình cao nhất trong số các mô hình quy mô 7B được đánh giá, đặc biệt xuất sắc trong hiểu biết âm nhạc. Trên bộ AudioCaps, Covo-Audio cũng đạt điểm số dẫn đầu. Biến thể hội thoại của nó thể hiện hiệu suất mạnh mẽ trong các nhiệm vụ lập luận bằng giọng nói và hội thoại, vượt trội so với các mô hình như Qwen-Audio-Chat.