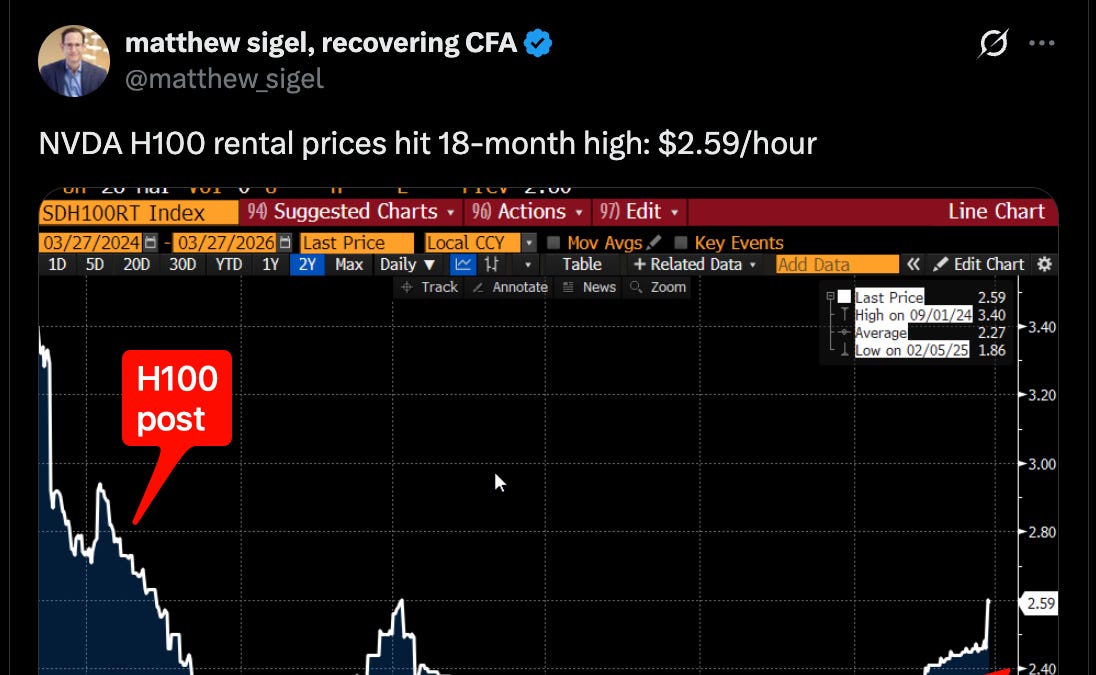
Giá H100 tăng bất chấp tuổi đời
Theo phân tích từ cộng đồng chuyên môn, H100 đang chứng minh giá trị lâu dài hơn nhiều so với dự kiến. Thông thường, chip GPU trong trung tâm dữ liệu có lịch khấu hao từ 4 đến 7 năm. Tuy nhiên, sự phát triển vượt bậc của các mô hình ngôn ngữ lớn (LLM) và phần mềm suy luận (reasoning) đã khiến utility (độ hữu dụng) của H100 ở thời điểm hiện tại còn cao hơn cả lúc mới ra mắt.
"Giá trị của H100 ngày nay thậm chí còn lớn hơn so với 3 năm trước"
Điều này xuất phát từ việc các mô hình AI và agent ngày càng thông minh hơn, tận dụng được sức mạnh phần cứng triệt để hơn, biến một con chip "già" thành tài sản có giá trị bền vững.
Tác động đến kinh tế token và mô hình kinh doanh
Xu hướng này được dự báo sẽ có tác động sâu sắc đến mô hình kinh doanh của các trung tâm dữ liệu và nhà cung cấp dịch vụ GPU đám mây. Nếu giá thuê tiếp tục tăng, chi phí vận hành và thuê ngoài điện toán AI cho training và inference có thể leo thang. Các startup và công ty phụ thuộc vào GPU thuê sẽ phải tính toán lại kế hoạch tài chính.
Bối cảnh cạnh tranh khốc liệt từ Anthropic và mô hình mã nguồn mở
Tin tức này xuất hiện trong bối cảnh căng thẳng hạ tầng AI đang gia tăng. Thông tin rò rỉ về Anthropic Mythos – tier cao cấp hơn cả Claude Opus với tên mã Capybara – cho thấy các công ty frontier AI đang đẩy mạnh chạy đua scale. Tier mới được đồn đoán có điểm số vượt trội về coding, academic reasoning và cybersecurity, nhưng bị giới hạn rollout do lo ngại về chi phí và an toàn.
Mặt khác, áp lực từ các mô hình mã nguồn mở cũng đang lớn dần. GLM-5.1 từ Trung Quốc đang thu hẹp khoảng cách với các mô hình coding độc quyền. Phân tích từ Arena leaderboard cho thấy chênh lệch giữa mô hình mở và đóng hiện nay đã nhỏ hơn rất nhiều so với một năm trước.
Xu hướng inference cục bộ (local) và tranh cãi quantization
Một chủ đề nổi bật khác là kinh tế inference cục bộ đang được cải thiện. Nhiều người dùng nhận thấy các mô hình local đã "đủ tốt" cho nhiều workflow, cho phép thay thế các dịch vụ đăng ký đắt đỏ. Các kỹ thuật quantization và quản lý cache vẫn là chìa khóa, với các giải pháp như vLLM tiếp tục được tối ưu hóa.
Tuy nhiên, không phải không có tranh cãi. Phương pháp TurboQuant hiện đang bị nghi ngờ về một số tuyên bố benchmark so sánh, đặc biệt là so sánh không công bằng giữa CPU và GPU. Điều này không làm mất đi giá trị kỹ thuật của TurboQuant, nhưng đặt dấu hỏi về các số liệu công bố.
Góc nhìn: Thị trường AI Việt Nam cần linh hoạt thích ứng
Việc giá GPU H100 tăng trở lại là hồi chuông cảnh báo cho hệ sinh thái AI non trẻ tại Việt Nam. Chi phí điện toán – yếu tố nền tảng – có thể tiếp tục là rào cản lớn.
Điều này đòi hỏi các công ty, startup và nhà nghiên cứu AI trong nước phải linh hoạt hơn trong chiến lược: tăng cường tối ưu hóa mô hình, khai thác các mô hình mã nguồn mở chất lượng cao, cân nhắc inference cục bộ và đa dạng hóa nhà cung cấp cloud. Trong bối cảnh cạnh tranh toàn cầu khốc liệt, việc quản lý hiệu quả chi phí hạ tầng sẽ là một lợi thế cạnh tranh quan trọng.


