Một nghiên cứu mới từ Alibaba đã cảnh báo về rủi ro tiềm ẩn khi nâng cấp mô hình AI: 75% AI coding agent phá vỡ code đang hoạt động sau khi chuyển đổi. Benchmark SWE-CI công bố tháng này cho thấy việc thay đổi mô hình ngôn ngữ lớn (LLM) có thể gây ra những thay đổi hành vi tinh vi mà các số liệu tổng hợp không thể phát hiện.
SWE-CI: Benchmark kiểm tra độ ổn định AI coding agent
SWE-CI là benchmark chuyên dụng được Alibaba phát triển để đánh giá liệu các AI coding agent có duy trì hành vi chính xác theo thời gian hay không. Kết quả nghiên cứu cho thấy 3/4 agent phá vỡ code trước đó đang hoạt động - và việc nâng cấp mô hình là một trong những nguyên nhân chính.
Vấn đề này không chỉ giới hạn ở coding agent. Mọi đội ngũ vận hành agent dựa trên LLM đều đối mặt với thách thức tương tự theo chu kỳ hàng quý: nhà cung cấp ngừng hỗ trợ model cũ, phiên bản mới hứa hẹn hiệu năng tốt hơn, hoặc việc chuyển đổi nhà cung cấp vì lý do chi phí.
Thử nghiệm bắt buộc hàng quý
Trước đây, việc ngừng hỗ trợ model thường diễn ra hàng năm. Giờ đây, chu kỳ này đã rút ngắn xuống hàng quý. Claude Opus 3 bị ngừng hỗ trợ đầu năm nay, GPT-4 Turbo bị sunset năm ngoái. Mỗi lần ngừng hỗ trợ buộc mọi đội ngũ sử dụng model đó phải di chuyển - không theo lịch trình của họ, mà theo lịch trình của nhà cung cấp.
Không chỉ vậy, các đội ngũ còn chuyển đổi model để tối ưu chi phí, cải thiện độ trễ hoặc nâng cấp khả năng. Mỗi lần chuyển đổi là một thử nghiệm bắt buộc với các biến số không được kiểm soát - model mới hoạt động khác nhau trên mọi tác vụ, và những khác biệt này vô hình trong số liệu tổng hợp.
Cách di chuyển che giấu sự suy giảm
Các model khác nhau có điểm mạnh khác nhau trên các loại tác vụ. GPT-4o có thể tốt hơn trong việc trích xuất có cấu trúc, trong khi Claude xuất sắc trong lập luận nhiều bước. Một model nhanh hơn có thể tạo ra phản hồi ngắn hơn - điều này trông giống như cải thiện chi phí cho đến khi bạn nhận ra các phản hồi ngắn hơn thực chất là thiếu sót.
Ví dụ điển hình: tỷ lệ thành công tăng từ 82% lên 83%, chi phí trung bình giảm từ $0.04 xuống $0.03, độ trễ trung bình giảm từ 6.2s xuống 5.8s. Những gì bị bỏ lỡ: 8 trong số 25 loại tác vụ bị suy giảm. Các tác vụ khối lượng lớn, độ phức tạp thấp được cải thiện nhẹ - làm phồng số liệu tổng hợp. Các luồng nghiệp vụ phức tạp chiếm 15% lưu lượng bị phá vỡ một cách thầm lặng.
Số liệu tổng hợp được cải thiện. Các loại tác vụ quan trọng bị suy giảm. Và không có gì trong các số liệu hàng đầu cảnh báo điều này.
Giải pháp: Phân tích chi tiết theo loại tác vụ
Hai phương pháp giúp phát hiện vấn đề khi số liệu tổng hợp trông ổn định:
Kiểm tra ý nghĩa thống kê: Chi phí thực sự giảm, hay 50 trace là không đủ để kết luận? Cần tính toán khoảng tin cậy bootstrap - nếu CI trên delta trung vị bao gồm số không, "cải thiện" không phải là thực tế, mà là nhiễu mẫu.
Phân tích theo loại tác vụ: Tác vụ nào tốt hơn? Tác vụ nào tệ hơn? Nếu 8 loại tác vụ chuyển từ pass sang fail, đó là sự suy giảm - ngay cả khi tổng thể tăng lên.
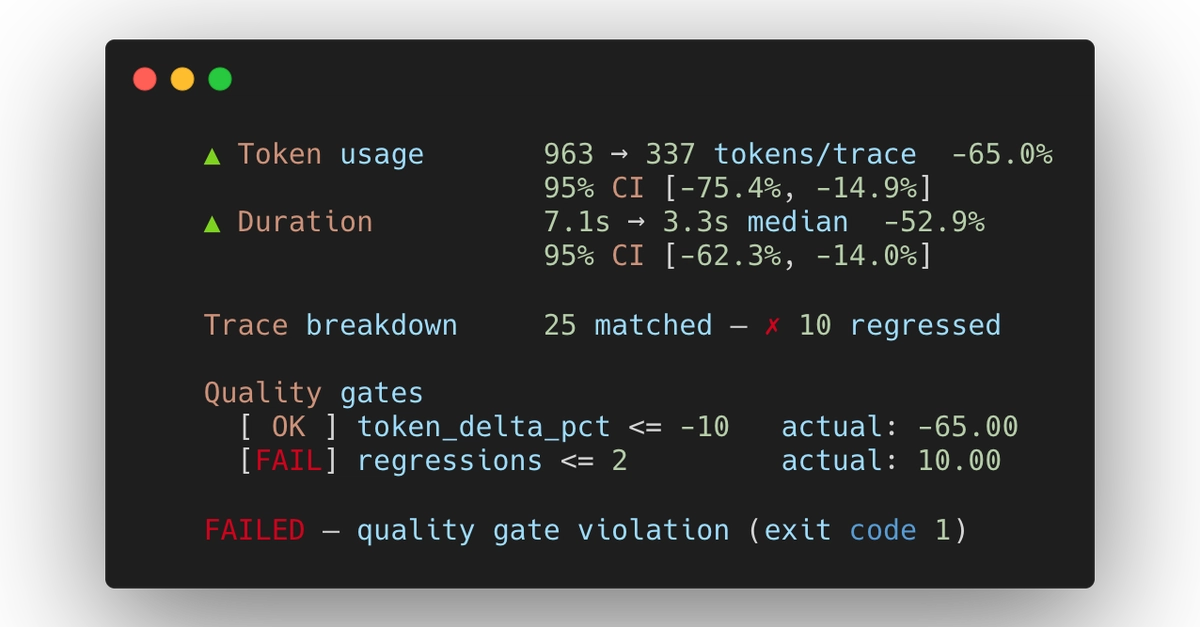
Công cụ Kalibra - một CLI mã nguồn mở so sánh hai quần thể trace một cách thống kê - minh họa rõ vấn đề này. Trong thử nghiệm với 25 tác vụ qua cùng một agent, baseline so với hiện tại, 50 trace mỗi bên, số liệu tổng hợp cho thấy cải thiện ở mọi nơi: token usage giảm 65%, duration giảm 52.9%. Tuy nhiên, 10 loại tác vụ bị phá vỡ. Token giảm vì phản hồi phức tạp bị cắt ngắn, không phải vì agent hiệu quả hơn.
Góc nhìn
Nghiên cứu này có ý nghĩa quan trọng với thị trường Việt Nam, nơi nhiều startup và doanh nghiệp đang tích cực ứng dụng AI coding assistant và LLM-powered agent. Việc nâng cấp model không đơn thuần là thay đổi cấu hình - đó là một thử nghiệm sản phẩm quy mô lớn với rủi ro tiềm ẩn. Các đội ngũ công nghệ Việt cần xây dựng quy trình đánh giá chi tiết theo loại tác vụ, thay vì chỉ dựa vào số liệu tổng hợp, để đảm bảo chất lượng hệ thống không bị suy giảm sau mỗi lần nâng cấp.


